아래 강의를 바탕으로 작성한 글이다.
https://www.inflearn.com/course/jpa-spring-data-%EA%B8%B0%EC%B4%88
[지금 무료]JPA & Spring Data JPA 기초 강의 | 최범균 - 인프런
최범균 | , DB 연동의 열쇠 JPA! 실무 중심의 핵심 기본기를 빠르게 🚀 백엔드 실무자를 위한 JPA & 스프링 데이터 JPA JPA & Spring Data JPA? [사진] JPA는 객체를 관계형 데이터베이스 테이블에 영속화해
www.inflearn.com

이미지에서 role 은 특정 역할, role_perm은 특정 역할에 대한 권한을 이야기 한다.
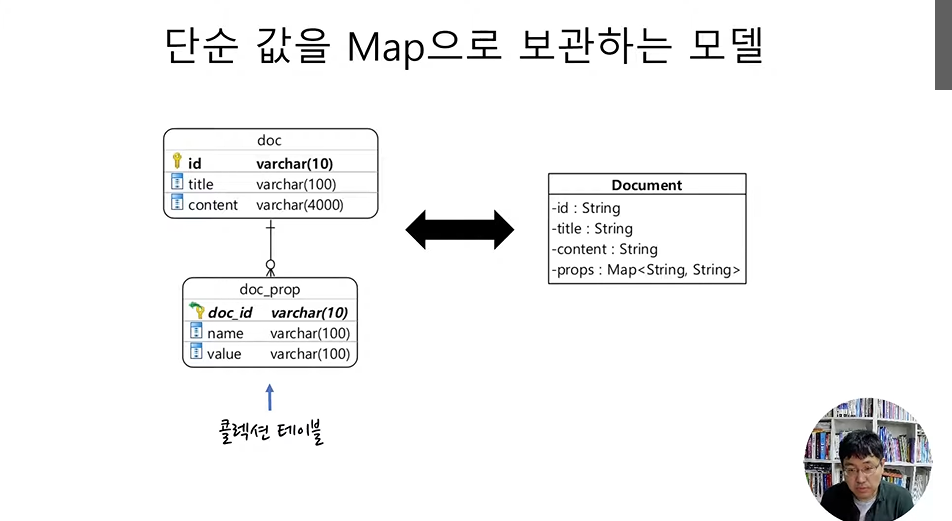
perm을 하나의 Set으로 보관하는 모델을 만들고자 할 때,
role_perm을 콜렉션 테이블이라고 표현한다.
단순 값 Set 매핑

사용 방법)
Set 필드에 @ElementCollection과 @CollectionTable 어노테이션을 사용한다.
CollectionTable#name : 콜렉션 테이블 이름 지정
JoinColumn : 외래키 지정
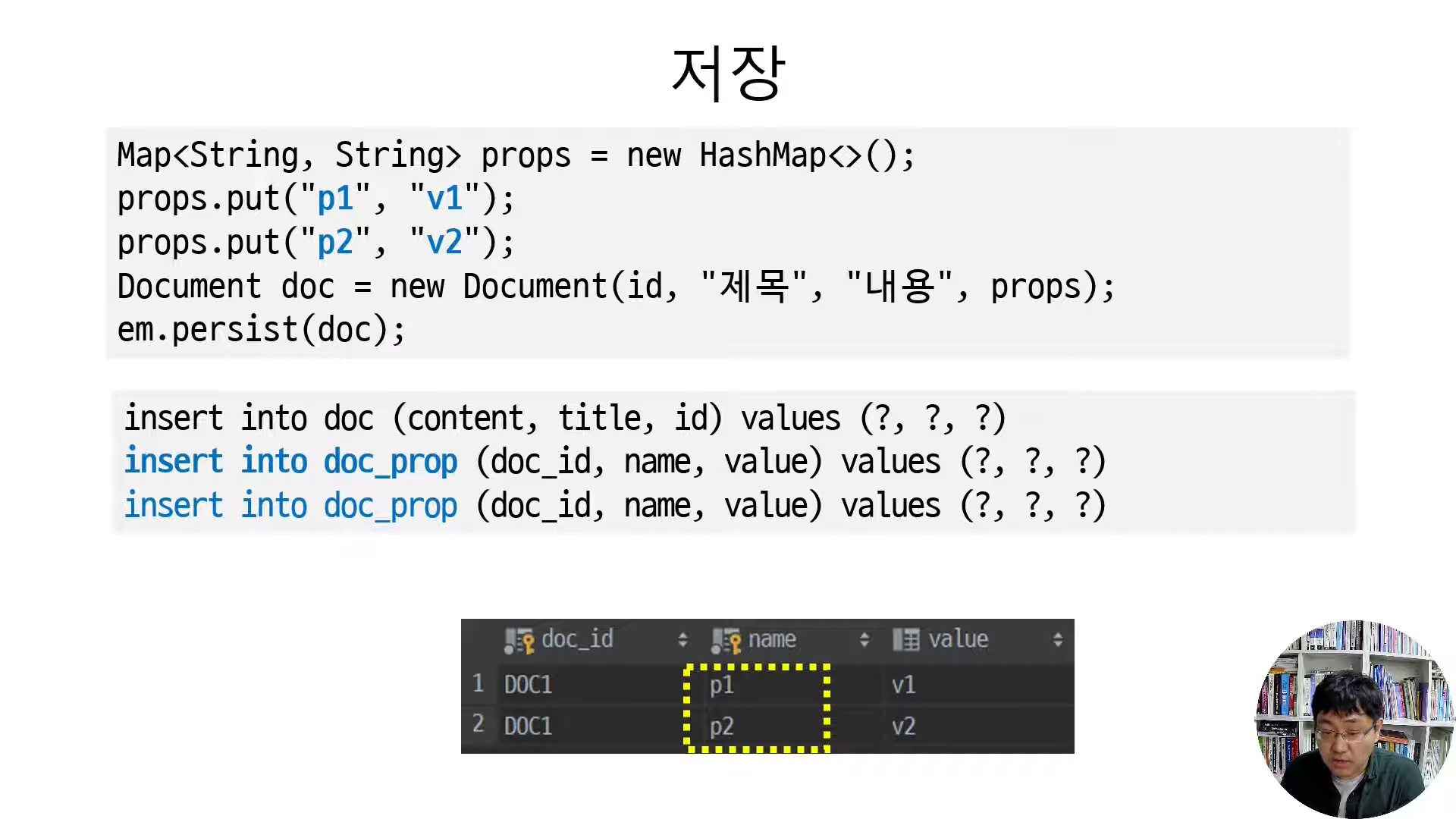
저장

Set에 보관된 데이터 개수만큼 insert 쿼리를 실행하는 것을 확인할 수 있다.
조회(lazy)


eager : role과 role_perm을 함께 불러와서 사용한다.
fetch를 FetchType.EAGER로 설정해서 사용한다.
Set 매핑의 기능





@Column을 삭제하고, @Embeddable 만 지정해주면 된다.

Set과 다르게 순서대로 저장된다.

set과 다르게 @OrderColumn을 통해 리스트 인덱스 값을 저장할 칼럼을 지정하면 된다.


eager : LEFTJOIN 으로 한방쿼리로

* 개별 인덱스를 추가하거나 제거하는 것도 가능하지만,
강사님 개인적으로는 잘 사용하지 않는다고 얘기하셨다.

컬렉션 테이블의 데이터를 삭제하고, 엔터티를 삭제한다.
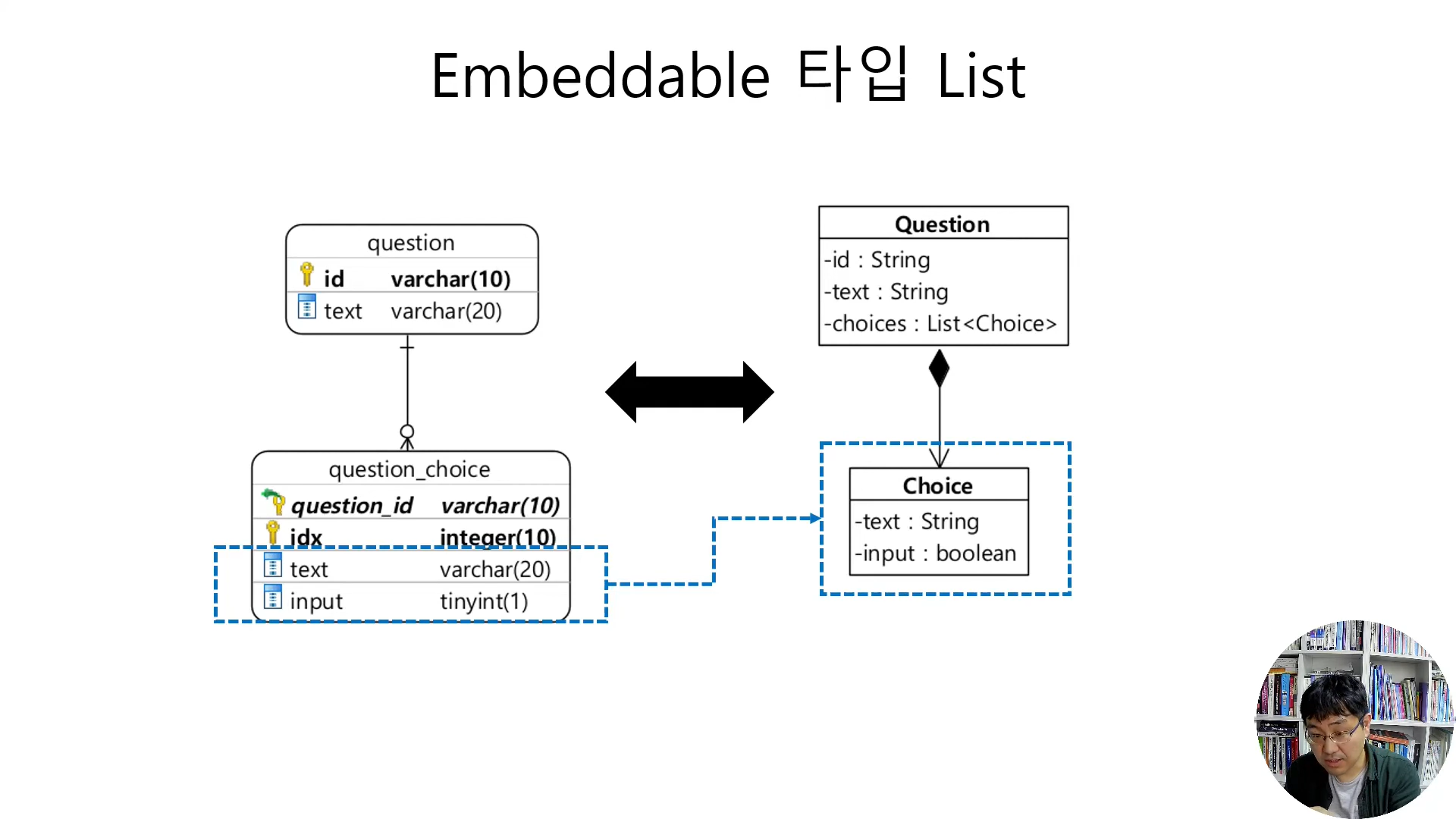

콜렉션 테이블을 이용한 값 List 매핑
- @ElementCollection과 @CollectionTable, @OrderColumn 이면 끝
기존과의 차이점은 @MapKeyColumn 을 이용해 Key 값을 저장한 칼럼을 지정해준다.




Map 매핑
@ElementCollection 과 @CollectionTable, @MapKeyColumn 을 사용하면된다.
값 콜렉션 주의사항
JPQL 에 대해서는 아직 공부하지 않았지만, 아래의 파란 글씨는 JPA에서 사용할 수 있는 언어로
작성된 쿼리이다.

위 @ElementColelction의 fetch를 EAGER로 주었지만,
실행하면 Lazy 처럼 role과 role-form이 따로 된다.
즉 , 쿼리가 더 많이 실행되고 있음을 알 수 있다.

permission을 처리하지 않기 위해 join fetch를 사용한다.
그러면 role과 role_perm을 join해서 읽어 올수 있다.
이렇게 사용하면 setFirstResult와 MaxResults의 설정과 상관없이 limit 없이 모두 다 읽을 수 있다.
그러고 나서 페이징 처리를 메모리가 하기 때문에 applying in memory 문구가 출력된다.
성능문제
- 설문 질문 목록을 보여줄 때 각 질문의 보기 개수를 함께 표시?
- 페이징 처리 필요
- 콜렉션 데이터 자체는 필요 없다.
- 역할 목록을 표시할 떄 가진 권한을 함께 표시?
- 페이징 처리 필요
- 각 역할마다 권한 조회 쿼리를 실행하고 싶지 않음
성능문제 -> CQRS
변경기능을 위한 모델과 조회 기능을 위한 모델을 분리
- 변경 기능 - JPA 활용
- 조회 기능 - My Batis / JdbcTemplate / JPA 중 알맞은 기술 사용
모든 기능을 JPA 로 구현할 필요 없음
-> 특히 목록, 상세와 같은 조회 기능
CQRS 관련 내용은 아래 참고
JPA를 다 사용하는 것보다는 모델 구분을 하면 더 편하다!
영속 컨텍스트 & 라이프 사이클


영속(Persistent) 엔터티/객체
- DB 데이터에 매핑되는 메모리상의 객체
영속 컨텍스트
- 일종의 메모리 저장소
- Entity Manager 가 관리할 엔티티 객체 보관
- (엔티티 타입, 식별자) = 엔티티 객체
EntityManager.close()
- 영속 컨텍스트 제거
- 배치 처리 X
* 알고있으면 좋은 라이프사이클

첫번째 find()를 실행할 때는 select 쿼리를 실행하지만, 두번째 find()는 select 쿼리를 실행하지 않는다.
그 이유는
첫번째 find 를 실행했을 때, 영속 컨텍스트에 영속 객체로 저장하기 때문에 추후 find 객체는 영속 컨텍스트에 보관된 객체에서 조회 후, 리턴된다.
영속 컨텍스트와 변경 추적


'Study' 카테고리의 다른 글
| [Git/Github] 협업을 위한 Github_간단 정리 (0) | 2025.03.15 |
|---|---|
| [소프트웨어 공학] 애자일(Agile) 방법론 (0) | 2025.03.03 |
| [점프 투 스프링 부트3] 프로젝트 구조 _ 게시판 프로젝트 (0) | 2025.02.24 |
| [점프 투 스프링 부트3] 웹 서비스의 동작 이해와 URL 매핑 (0) | 2025.02.17 |
| [자바 ORM 표준 JPA 프로그래밍] 2장. JPA 시작하기 (1) | 2025.02.03 |