이 글은 DeepMind의 David Silver가 진행한 RL 강의 중 Lecture 1: Introduction to Reinforcement Learning의 주요 내용을 정리한 것이다.
강화학습이란?
기계학습(Machine Learning)은 크게 세 가지 유형으로 나뉜다.
- 지도학습 (Supervised Learning): 정답(label)이 있는 데이터를 기반으로 학습하는 방식이다.
- 비지도학습 (Unsupervised Learning): 정답 없이 데이터의 패턴을 찾는 방식이다.
- 강화학습 (Reinforcement Learning): 정답은 없고 보상(Reward)을 통해 학습하는 방식이다.
강화학습의 특징은 다음과 같다.
| 특징 | 설명 |
|---|---|
| 감독 없음 | 정답 대신 보상만 주어진다. |
| 피드백 지연 | 행동에 대한 결과(보상)가 바로 주어지지 않을 수 있다. |
| 시간 순서 중요 | 행동이 이후 상태와 보상에 영향을 미친다. |

강화학습의 예시들
- 헬리콥터의 곡예 비행 제어
- 인간보다 뛰어난 아타리 게임 플레이
- 투자 포트폴리오의 자율적 운용
- 휴머노이드 로봇의 걷기 제어
- 전문가 수준의 보드게임 플레이 (예: 백개먼)
이처럼 강화학습은 시행착오를 통해 스스로 행동을 개선해 나가는 학습 방식이다.
Rewards
All goals can be described by the maximisation of expected cumulative reward
모든 목적이 누적된 reward 를 최대화 하는 것으로 표현할 수 있다는 가정
리워드함수 Rt는 스칼라 피드백 시그널이다. -> t번째 타임에 Rt만큼의 시그널이 주어진다.
에이전트가 각 스텝 t마다 얼마나 잘하고 있는지 알려준다.
에이전트의 일은 누적된 보상(cumulative reward)을 최대화하는 것이다.
ex) 한 게임이 끝날때까지 받는 데이터를 축적시켜서 최대화하는 것이다.
강화학습의 기본 구조
강화학습은 에이전트(Agent)와 환경(Environment) 사이의 상호작용을 중심으로 진행된다.

에이전트는 매 시점에서 행동(action)을 선택하며, 이에 따라 환경은 관찰(observation)과 보상(reward)을 반환한다. 이러한 반복적인 상호작용을 통해 학습이 진행된다.
History And State
History는 observations, actions, rewards를 순서에 따라 모아둔 것이다.
-> 그 시간 t 까지 있었던 각각의 timestamp마다 Agent가 수행한 action, observation, reward를 순차적으로 기록한 것
Agent는Action을 결정한다.
Environment는 observation과 reward를 결정한다.
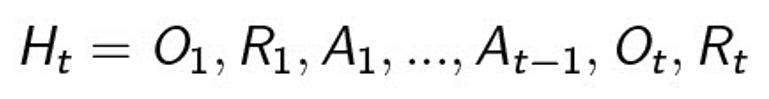
State는 다음에 어떤것을 진행할 지 결정하는데 사용되는 정보이다.
Agent는 다음액션을 결정하기 위해 숫자를 사용한다.
Environment도 Observation과 Reward를 제공하기 위해 숫자를 사용한다.
앞에 언급된 숫자를 State라고한다.
State란, 다음 행동에 쓰이는 모든 정보를 이야기한다.
-> 무엇을 선택하기 위해서 과거를 보는 것은 당연하다.
State는 History의 함수이다.
History의 정보를 가공하여 State를 만든다.
관점에 따른 State
Environment State
- environment가 Next observation과 reward를 계산하기 위해 사용한 모든 정보
ex) Atari game에서 Agent가 선택한 Action에 따라 표기되는 다음 화면(observation)을 계산하기 위해 참고하는 정보들
공의 위치, 현재 박스의 개수 및 구조 등
- State는 보통 Agent에게 보이지 않는다. (너무 복잡한 정보이기 때문에 활용하지않는다.)
Agent State
- Agent가 Next Action을 select 하기 위해 참고하는 정보(직접 정하는 것)
Information State - Marcov state
Definition
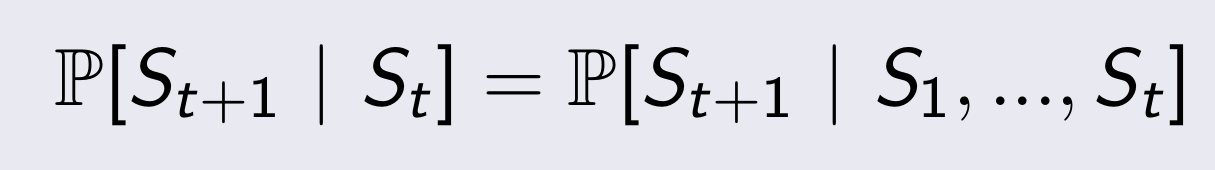
- 과거와 미래는 독립적이다.
- 미래를 결정할 때 이전의 State는 필요없고 바로 이전의 State만을 참고하여 결정을 내린다.
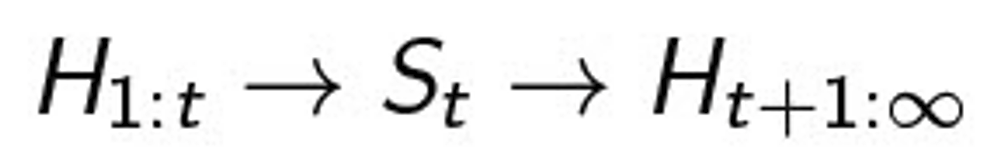
Markov State 예시
Rat
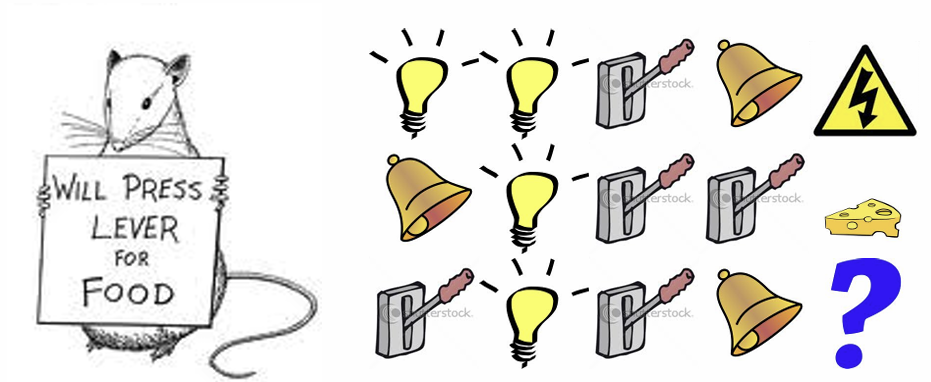
1. 최근 3가지의 signal을 state로 정의한다면 : 감전
2. 전체 History에서 각 signal이 등장한 횟수를 state로 정의한다면 : 치즈
결론
History에 대한 Function을 어떻게 정의하는지에 따라 같은 데이터라도 다르게 예측할 수 있다.
Fully Observability
- Environment의 State를 Agent가 볼 수 있는 상황
- Markov decision process : MDP
- Agent State = Environment state = Information state
Partially Observability
- partially observable Markov decision process : POMDP
- Agent state와 Environment state가 다르다.
-> 따라서 Agent는 자신의 State를 표현하기위한 방법을 구축해야한다.
Agent의 State 표현 예시
Complete history
Beliefs of environment state
Recurrent Neural network
'Study' 카테고리의 다른 글
| [강화학습] Introduction_RL_2 (0) | 2025.04.08 |
|---|---|
| [Git/Github] 협업을 위한 Github_간단 정리 (0) | 2025.03.15 |
| [소프트웨어 공학] 애자일(Agile) 방법론 (0) | 2025.03.03 |
| [JPA] 컬렉션과 연관 매핑 (0) | 2025.02.24 |
| [점프 투 스프링 부트3] 프로젝트 구조 _ 게시판 프로젝트 (0) | 2025.02.24 |