이 글은 Introduction_RL_1 포스팅과 이어지는 글입니다.
2025.04.05 - [Study] - [강화학습] 1.Introduction_RL_1
[강화학습] 1.Introduction_RL_1
이 글은 DeepMind의 David Silver가 진행한 RL 강의 중 Lecture 1: Introduction to Reinforcement Learning의 주요 내용을 정리한 것이다.강화학습이란?기계학습(Machine Learning)은 크게 세 가지 유형으로 나뉜다.지도학
dev-hyena.tistory.com
강화학습의 핵심 개념
- 보상 (Reward): 에이전트의 행동 결과에 대한 수치적 피드백이다.
- 상태 (State): 현재 상황을 나타내는 정보로, 과거의 기록(Ht)으로부터 정의된다.
- 정책 (Policy): 각 상태에서 어떤 행동을 선택할지 결정하는 함수이다.
- 가치 함수 (Value Function): 특정 상태 또는 행동의 장기적인 기대 보상을 예측한다.
- 모델 (Model): 다음 상태나 보상을 예측하는 내적 시뮬레이션이다.
강화학습 에이전트의 구성요소
Agent는 3가지 구성요소를 모두 가질수도, 하나만 가질수도 있다.
| Policy | Agent's behaviour function |
| Value Function | how good is each state and/or action |
| Model | Agent's representation of the environment |
Policy
- A policy is the Agent's behaviour
state를 입력으로 전달하면, action을 반환한다. -> state와 action을 mapping
Policy의 종류
- deterministic policy : state에 대하여 하나의 action을 정확히 결정하여 반환한다.
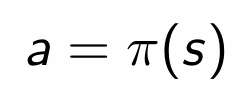
- stochastic policy : state에 대하여 여러가지 action이 가능한데, 이때 각각의 action에 대한 확률을 반환한다.
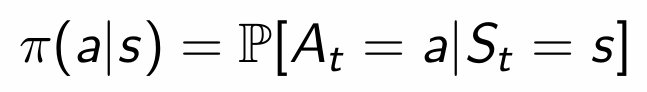
Value Function
Value Function is a prediction of future reward
: 가치함수는 미래 보상에 대한 예측이다.
- 현재의 state가 얼마나 좋은지 평가한다.
- 현재로부터 미래까지 받을 수 있는 모든 Reward의 합에 대한 기댓값으로 표현할 수 있다.
Formal
s : 현재 state를 의미
v : value function을 의미한다 -> Agent가 어떤 policy를 따라서 진행하는 것을 나타낸다.
E : 여러가지 가능한 모든 episode가 존재하기 때문에 기댓값을 사용하여 나타낸다.
r : 미래의 reward에 대한 가중치를 줄여서 나타내기 위한 상수값

Model
Model predits what the environment will do next
- Environment 가 어떻게 변화할지 예측하는 요소
- Environment의 역할 (= state의 변화, reward전달)을 Agent가 Model을 이용하여 예측해서 표현
Model의 종류
P predicts the next state = state의 transition 예측
R predicts the next (immediate) reward
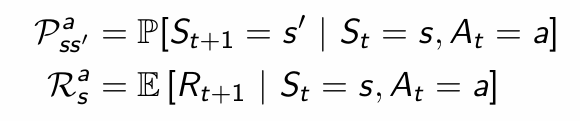
Policy와 Value에 따른 분류
Policy와 Value에 따른 분류
- Value Based
- No Policy
- Value Function
- Policy Based
- Policy
- No Value Function
- Actor Critic
- Policy
- Value Function
Model에 따른 분류
- Model Free
- Policy and/or Value Function
- No Model
- Model Based
- Policy and/or Value Function
- Model
탐험과 이용의 균형: Exploration vs Exploitation
강화학습에서는 다음의 두 가지 사이에서 균형을 잡는 것이 중요하다.
- 탐험(Exploration): 새로운 행동을 시도하여 더 나은 결과를 탐색한다.
- 이용(Exploitation): 현재까지의 경험을 바탕으로 최선이라고 생각되는 행동을 선택한다.
현실 세계에서의 예시는 다음과 같다.
- 음식점 선택: 익숙한 맛집을 계속 갈 것인가, 새로운 곳을 시도할 것인가
- 광고 배너: 클릭률이 높은 광고를 계속 보여줄 것인가, 새로운 광고를 테스트할 것인가
- 투자 전략: 검증된 종목에 집중할 것인가, 신생 종목에 투자할 것인가
'Study' 카테고리의 다른 글
| [강화학습] 1.Introduction_RL_1 (0) | 2025.04.05 |
|---|---|
| [Git/Github] 협업을 위한 Github_간단 정리 (0) | 2025.03.15 |
| [소프트웨어 공학] 애자일(Agile) 방법론 (0) | 2025.03.03 |
| [JPA] 컬렉션과 연관 매핑 (0) | 2025.02.24 |
| [점프 투 스프링 부트3] 프로젝트 구조 _ 게시판 프로젝트 (0) | 2025.02.24 |